Generate environments for training#
This notebooks explains how you can either use our example curriculum for your training or generate environments yourself.
All environments share the competition topology, however, the lines used and the number of agents vary.
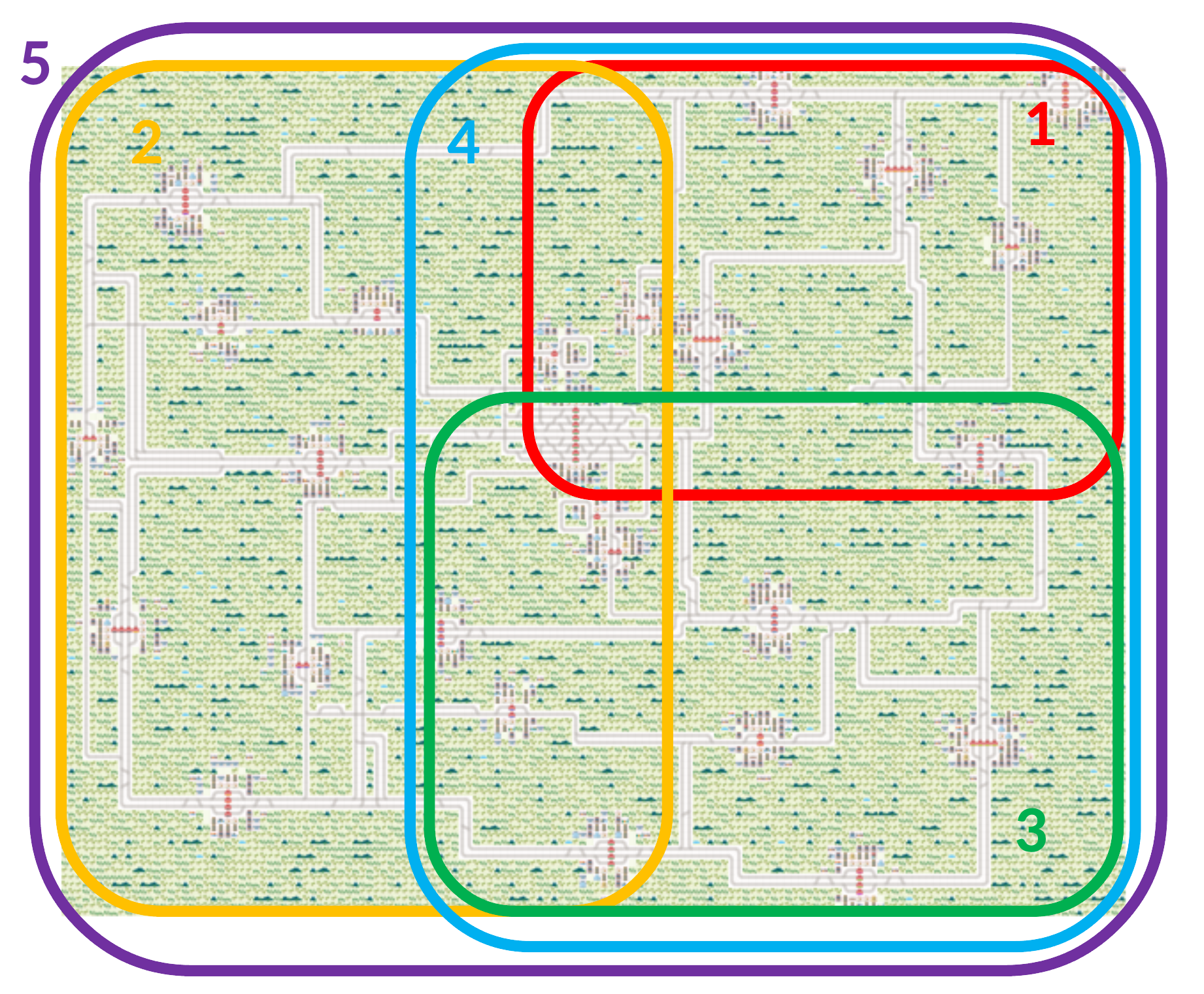
Loading competition environments from ecml2026-starterkit (example curriculum)#
from flatland.envs.persistence import RailEnvPersister
from flatland.utils.rendertools import RenderTool
import PIL
# !rm -fR ecml2026-starterkit
!git clone -q https://github.com/flatland-association/ecml2026-starterkit
import sys
sys.path.insert(0, "ecml2026-starterkit")
!unzip ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum.zip -d ecml2026-starterkit/reinforcement_learning/curriculum/
Archive: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum.zip
creating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/00_scene_1_ll-2_a-1.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/01_scene_4_ll-2_a-1.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/02_scene_5_ll-2_a-1.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/03_scene_1_ll-2_a-10.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/04_scene_4_ll-2_a-10.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/05_scene_5_ll-2_a-10.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/06_scene_1_ll-2_a-25.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/07_scene_4_ll-2_a-25.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/08_scene_5_ll-2_a-25.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/09_scene_1_ll-3_a-1.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/10_scene_4_ll-3_a-1.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/11_scene_5_ll-3_a-1.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/12_scene_1_ll-3_a-10.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/13_scene_4_ll-3_a-10.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/14_scene_5_ll-3_a-10.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/15_scene_1_ll-3_a-25.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/16_scene_4_ll-3_a-25.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/17_scene_5_ll-3_a-25.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/18_scene_1_ll-4_a-1.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/19_scene_4_ll-4_a-1.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/20_scene_5_ll-4_a-1.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/21_scene_1_ll-4_a-10.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/22_scene_4_ll-4_a-10.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/23_scene_5_ll-4_a-10.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/24_scene_1_ll-4_a-25.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/25_scene_4_ll-4_a-25.pkl
inflating: ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/26_scene_5_ll-4_a-25.pkl
env, _ = RailEnvPersister.load_new("ecml2026-starterkit/reinforcement_learning/curriculum/example_curriculum/00_scene_1_ll-2_a-1.pkl")
The parameters in the provided example environments are described in the ecml2026-starterkit.
env_renderer = RenderTool(env)
image = env_renderer.render_env(show=False, show_observations=False, show_predictions=False, return_image=True)
display(PIL.Image.fromarray(image))

Generate new environments#
Using the ecml2026-starterkit, new environments can be generated (see ecml2026.md for details on the scenes). From within the starterkit, use:
from reinforcement_learning.create_curriculum_envs import create_curriculum_env
env = create_curriculum_env(
scenario_path="ecml2026-starterkit/reinforcement_learning/sampling/level_0_scenario_1.pkl",
# using this as input provides the infrastructure map from the competition, all other parameters can be overridden, e.g. scene (stations), number of agents and line length
scene="scene_1", # choose from: "scene_1", "scene_2", "scene_3", "scene_4", "scene_5"
n_agents_range=None,
# uses the number given in the .pkl as default, can be set to a tuple (min_n_agents, max_n_agents) to sample a random number of agents from the given range
line_length=2, # default is 2, has to be >= 2
)
Deep-Dive Line Generation#
agent = env.agents[0]
agent
EnvAgent(initial_configuration=((51, 72), 1), current_configuration=None, targets={((3, 145), <Grid4TransitionsEnum.WEST: 3>), ((3, 145), <Grid4TransitionsEnum.EAST: 1>)}, moving=False, earliest_departure=0, latest_arrival=142, waypoints=[[Waypoint(position=(51, 72), direction=1)], [Waypoint(position=(38, 89), direction=0), Waypoint(position=(38, 90), direction=0), Waypoint(position=(38, 91), direction=0), Waypoint(position=(38, 92), direction=0)], [Waypoint(position=(14, 116), direction=0), Waypoint(position=(14, 117), direction=0), Waypoint(position=(14, 118), direction=0), Waypoint(position=(14, 119), direction=0)], [Waypoint(position=(2, 141), direction=1), Waypoint(position=(3, 141), direction=1), Waypoint(position=(4, 141), direction=1), Waypoint(position=(5, 141), direction=1)], [Waypoint(position=(3, 145), direction=None)]], waypoints_earliest_departure=[0, 37, 96, 136, None], waypoints_latest_arrival=[None, 35, 94, 134, 142], handle=0, speed_counter=speed: 1 max_speed: 1 distance: 0 is_cell_entry: True, action_saver=is_action_saved: False, saved_action: None, state_machine=TrainStateMachine(
state=TrainState.WAITING,
previous_state=None,
st_signals=StateTransitionSignals(in_malfunction=False, earliest_departure_reached=False, stop_action_given=False, movement_action_given=False, target_reached=False, movement_allowed=False, new_speed_zero=False)
), malfunction_handler=MalfunctionHandler(
malfunction_down_counter=0,
num_malfunctions=0,
), arrival_time=None, old_configuration=None)
Lines consist of a sequence of “flexible waypoints” (a set of routing alternatives). The first waypoint is always unique and the last is a waypoint whose direction is None (meaning the cell can be reached from any direction). Here’s an example:
agent.waypoints[0]
[Waypoint(position=(51, 72), direction=1)]
agent.waypoints[-1]
[Waypoint(position=(3, 145), direction=None)]
However, lines can consist of more than source and target, namely, intermediate stops. For intermediate stops, it does not matter which of the cells belonging to a given station the agent stops at. This provides flexibility when routing the agents:
agent.waypoints
[[Waypoint(position=(51, 72), direction=1)],
[Waypoint(position=(38, 89), direction=0),
Waypoint(position=(38, 90), direction=0),
Waypoint(position=(38, 91), direction=0),
Waypoint(position=(38, 92), direction=0)],
[Waypoint(position=(14, 116), direction=0),
Waypoint(position=(14, 117), direction=0),
Waypoint(position=(14, 118), direction=0),
Waypoint(position=(14, 119), direction=0)],
[Waypoint(position=(2, 141), direction=1),
Waypoint(position=(3, 141), direction=1),
Waypoint(position=(4, 141), direction=1),
Waypoint(position=(5, 141), direction=1)],
[Waypoint(position=(3, 145), direction=None)]]
Note: stops at intermediate stops are not enforced, i.e. an agent does not have to stop at or can even omit intermediate waypoints altogether, however, it is penalized accordingly.
Sampling lines for training can be done by randomly picking stations. For intermediate stops, a list of waypoints, i.e. all cells belonging to the station, is provided.
Deep-Dive Schedules#
The timetable consist of time windows for each waypoint, an earliest arrival and a latest departure time. For the source (first waypoint), latest arrival is undefined, for the final target (last waypoint), earliest departure is undefined:
agent.waypoints_earliest_departure
[0, 37, 96, 136, None]
agent.waypoints_latest_arrival
[None, 35, 94, 134, 142]
Interpreation: if we take the first intermediate stop \(k=1\), then
k = 1
[agent.waypoints_latest_arrival[k], agent.waypoints_earliest_departure[k]]
[35, 37]
defines a time window for passing any one of
agent.waypoints[k]
[Waypoint(position=(38, 89), direction=0),
Waypoint(position=(38, 90), direction=0),
Waypoint(position=(38, 91), direction=0),
Waypoint(position=(38, 92), direction=0)]
reflecting “routing flexibility”.
In our sampling, timetables are generated for each agent according to their lines. For each line the shortest path connecting the waypoints is calculated (only for the first cell for intermediate stops). Multiplying the shortest time, which takes into account the agents max_speed, with a travel factor (>1) provides the time window (latest arrival, earliest departure) for the selected waypoints. The same logic applies to the evaluation environments, where different travel factors are used for different levels (see levelconfig.md).
Note again that the environment does not keep track of intermediate waypoints, i.e. an agent does not have to stop at or even pass an intermediate waypoint. The environment only enforces that an agent cannot enter Flatland before earliest departure defined for the agent’s initial waypoint. However, the reward-function evaluates whether trains have passed and stopped all waypoints in the requested time windows and will penalize otherwise.